![]() Reference: Mark Nelson, "The Data Compression Book", 2nd ed.,
M&T Books, 1995. QA 76.9 D33 N46 1995
Reference: Mark Nelson, "The Data Compression Book", 2nd ed.,
M&T Books, 1995. QA 76.9 D33 N46 1995
![]() Reference: Khalid Sayood, "Introduction to Data Compression",
Morgan Kaufmann, 1996. TK 5102 92 S39 1996
Reference: Khalid Sayood, "Introduction to Data Compression",
Morgan Kaufmann, 1996. TK 5102 92 S39 1996
![]()

 indicates the amount of information
contained in Si, i.e., the number of bits needed to code Si.
indicates the amount of information
contained in Si, i.e., the number of bits needed to code Si.
A simple example will be used to illustrate the algorithm:
|
Symbol |
A |
B |
C |
D |
E |
|
Count |
15 |
7 |
6 |
6 |
5 |
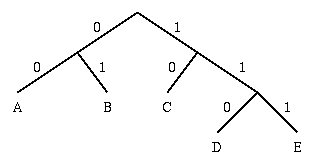
1. Sort symbols according to their frequencies/probabilities, e.g., ABCDE.
2. Recursively divide into two parts, each with approx. same number of
counts.
|
Symbol |
Count |
log2(1/pi) |
Code |
Subtotal (# of bits) |
|
A |
15 |
1.38 |
00 |
30 |
|
B |
7 |
2.48 |
01 |
14 |
|
C |
6 |
2.70 |
10 |
12 |
|
D |
6 |
2.70 |
110 |
18 |
|
E |
5 |
2.96 |
111 |
15 |
TOTAL (# of bits): 89
1. Initialization: Put all nodes in an OPEN list, keep it sorted at all times (e.g., ABCDE).
2. Repeat until the OPEN list has only one node left:
(a) From OPEN pick two nodes having the lowest
frequencies/probabilities, create a parent node of them.
(b) Assign the sum of the children's frequencies/probabilities to the
parent node and insert it into OPEN.
(c) Assign code 0, 1 to the two branches of the tree, and delete
the children from OPEN.

|
Symbol |
Count |
log2(1/pi) |
Code |
Subtotal (# of bits) |
|
A |
15 |
1.38 |
0 |
15 |
|
B |
7 |
2.48 |
100 |
21 |
|
C |
6 |
2.70 |
101 |
18 |
|
D |
6 |
2.70 |
110 |
18 |
|
E |
5 |
2.96 |
111 |
15 |
TOTAL (# of bits): 87
In the above example:
entropy = (15 x 1.38 + 7 x 2.48 + 6 x 2.7 + 6 x 2.7 + 5 x 2.96) / 39
= 85.26 / 39 = 2.19
Number of bits needed for Human Coding is: 87 / 39 = 2.23
(a) The previous algorithms require the statistical knowledge which is
often not available (e.g., live audio, video).
(b) Even when it is available, it could be a
heavy overhead especially when many tables had to be sent when
a non-order0 model is used, i.e. taking
into account the impact of the previous symbol to the probability of the
current symbol (e.g., "qu" often come together, ...).
The solution is to use adaptive algorithms. As an example, the Adaptive Huffman Coding is examined below. The idea is however applicable to other adaptive compression algorithms.
ENCODER DECODER
------- -------
Initialize_model(); Initialize_model();
while ((c = getc (input)) != eof) while ((c = decode (input)) != eof)
{ {
encode (c, output); putc (c, output);
update_model (c); update_model (c);
} }

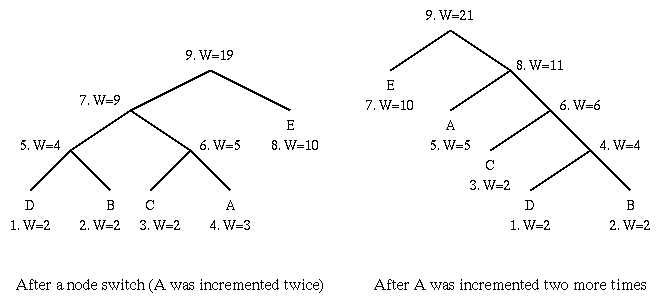
Note: Code for a particular symbol changes during the adaptive coding process.
Suppose we want to encode the Webster's English dictionary which contains about 159,000 entries. Why not just transmit each word as an 18 bit number?
Problems: (a) Too many bits, (b) everyone needs a dictionary, (c) only works for English text.
![]() Reference:
Terry A. Welch, "A Technique for High Performance Data Compression",
IEEE Computer, Vol. 17, No. 6, 1984, pp. 8-19.
Reference:
Terry A. Welch, "A Technique for High Performance Data Compression",
IEEE Computer, Vol. 17, No. 6, 1984, pp. 8-19.
LZW Compression Algorithm:
w = NIL;
while ( read a character k )
{
if wk exists in the dictionary
w = wk;
else
add wk to the dictionary;
output the code for w;
w = k;
}
Example: Input string is "^WED^WE^WEE^WEB^WET".
|
w |
k |
Output |
Index |
Symbol |
|
NIL |
^ |
|||
|
^ |
W |
^ |
256 |
^W |
|
W |
E |
W |
257 |
WE |
|
E |
D |
E |
258 |
ED |
|
D |
^ |
D |
259 |
D^ |
|
^ |
W |
|||
|
^W |
E |
256 |
260 |
^WE |
|
E |
^ |
E |
261 |
E^ |
|
^ |
W |
|||
|
^W |
E |
|||
|
^WE |
E |
260 |
262 |
^WEE |
|
E |
^ |
|||
|
E^ |
W |
261 |
263 |
E^W |
|
W |
E |
|||
|
WE |
B |
257 |
264 |
WEB |
|
B |
^ |
B |
265 |
B^ |
|
^ |
W |
|||
|
^W |
E |
|||
|
^WE |
T |
260 |
266 |
^WET |
|
T |
EOF |
T |
read a character k;
output k;
w = k;
while ( read a character k ) /* k could be a character or a code. */
{
entry = dictionary entry for k;
output entry;
add w + entry[0] to dictionary;
w = entry;
}
Example (continued):
Input string is "^WED<256>E<260><261><257>B<260>T".
|
w |
k |
Output |
Index |
Symbol |
|
^ |
^ |
|||
|
^ |
W |
W |
256 |
^W |
|
W |
E |
E |
257 |
WE |
|
E |
D |
D |
258 |
ED |
|
D |
<256> |
^W |
259 |
D^ |
|
<256> |
E |
E |
260 |
^WE |
|
E |
<260> |
^WE |
261 |
E^ |
|
<260> |
<261> |
E^ |
262 |
^WEE |
|
<261> |
<257> |
WE |
263 |
E^W |
|
<257> |
B |
B |
264 |
WEB |
|
B |
<260> |
^WE |
265 |
B^ |
|
<260> |
T |
T |
266 |
^WET |
Top | Chap 4 | CMPT 365 Home Page | CS