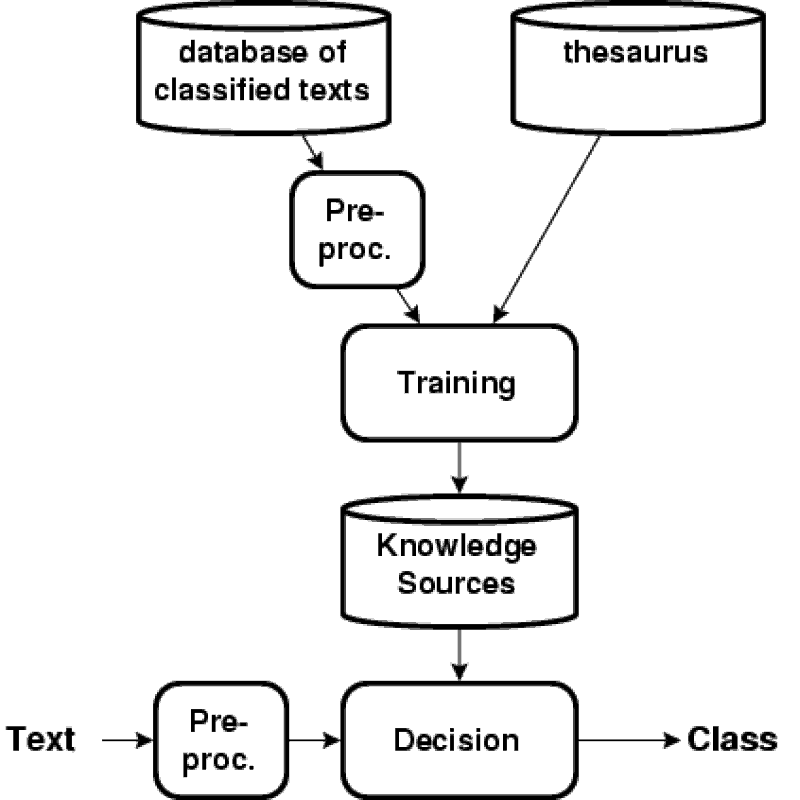
Architecture of a Text Classification System
| Text Classification and Clustering |
Text Classification and Clustering
Text classification is a fundamental task in document processing. The use
of statistical methods for this task are very promising as
opposed to rule-based and linguistically motivated methods. For
clustering tasks statistical criteria often outperform linguistic
based methods as well.
For the methods named above, different approaches in the statistical framework were tested on several corpora. The developed systems are very robust and give very good results, even on difficult corpora and languages. Experiments were performed on the Reuters corpus and on some Arabic corpora.