Alignment between a source and a target language sentence
| Ongoing Research in Machine Translation |
Improved Word Alignment Methods
A key component in statistical machine translation systems is the
so called alignment model. It structures the dependencies and
reorderings
between words between a source language text and its translation. We
investigated various alignment models and training procedures and
developed new alignment models which yield a significantly better
performance. In addition, we developed evaluation criteria and created
test corpora in order to assess the quality of various alignment models. We
showed that this evaluation criterion is correlated with
translation quality. On the VERBMOBIL corpus the subjective
sentence error rate was reduced from 22.2% to 16.8% when reducing
the alignment error rate from 16.0% to 6.5%.
Statistical Machine Translation with Alignment Templates
The alignment template system is a machine translation system which
is an extension of the baseline single-word based translation
models typically investigated in statistical machine
translation. The key element of this approach are the alignment
templates which are pairs of phrases together with an alignment
between the words within the phrases. The advantage of the
alignment template approach over word based statistical translation
models is that word context and local re-orderings are explicitly
taken into account. We typically observe that this approach
produces better translations than the single-word based models. The
alignment templates are automatically trained using a parallel
training corpus. The final evaluation of the VERBMOBIL project
showed that this approach yields significantly better translation
results than other classical translation methods such as rule-based
translation or example-based translation.
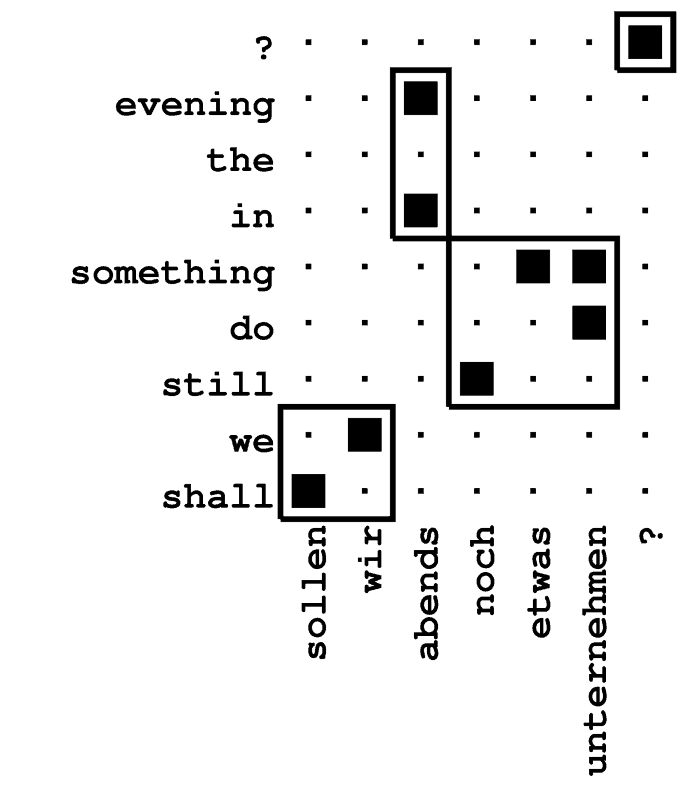
Search for Single-Word Based Statistical Machine Translation
In this approach to statistical machine translation, the dependencies
between the source and the target language are modelled on the basis of
single words. As Figure shows, the word order in source
and target language can be quite different. For the translation of each source sentence,
many possible reorderings of the corresponding words in the target
language have to be taken into
account. This results in a large space of possible hypotheses that
has to be searched in order to find the target sentence with the highest
probability.
Two different search algorithms have been implemented. One is based on a dynamic programming approach to the Traveling Salesman Problem. The source sentence positions can be regarded as the cities that have to be visited. Various methods were used in order to reduce the size of the search space, so called pruning techniques.
Another approach is based on the A* algorithm developed in
artificial intelligence. It uses a so called heuristic function to
estimate the remaining probability for the completion of a partial
hypothesis. This approach guarantees to find the optimal result
assuming that memory and CPU time are unlimited.
Experiments were performed in the so called Hansards corpus consisting
of the proceedings of the Canadian parliament that are kept both in
French and in English. The average translation
time per sentence was 11 seconds for the dynamic programming based
algorithm and 125 seconds for the A* based algorithm.
Morpho-Syntactic Analysis for Reordering in Statistical Machine Translation
In the framework of statistical machine translation, correspondences
between the words in the source and the target language are learned
from bilingual corpora using so called alignment
models, which among other things are meant to capture the differences in word order in
source and target language.
We have shown that statistical machine translation can take advantage of the explicit introduction of some information from morpho-syntactic analysis of the sentences in source and target language. We have focused on two aspects of reordering for the language pair German and English, namely question inversion and detachable German verb prefixes. For the experiments we used the alignment template translation system. We obtained an improvement of the SSER (manually evaluated subjective sentence error rate) from 32.5% to 30.0% on a test corpus comprising 251 sentences from the VERBMOBIL appointment scheduling and travel arrangement domain, which were translated form German into English. On a test set of 248 English sentences we achieved an improvement of the German translation from 36.3% SSER to 34.6%.
Toward hierarchical models for statistical machine translation
of inflected languages
In many applications only small amounts of bilingual training
data are available for the desired domain and language pair, and it is
highly desirable to avoid at least parts of the costly data collection
process.
On the other hand, monolingual knowledge sources
like morphological analyzers and data for training the target language
model as well as conventional dictionaries (one word and its
translation per entry)
may be available and of substantial usefulness for improving the
performance of statistical translation systems.
This is especially the case for highly inflected languages like German.
Existing statistical systems for machine translation often treat different
derivatives of the same lemma as if they were independent of each other.
We haven taken the interdependencies of the different
derivatives into account in order to achieve a better exploitation of
the corpora for training the model parameters.
We did this along two directions: Usage of
hierarchical lexicon models and the introduction of
equivalence classes in order to ignore information
not relevant for the translation task.
The equivalence classes yielded an improvement of the translation quality from 38.0%
to 36.7% SSER on the German-English test sentences mentioned
above using the combination of all the reordering methods.
First experiments for hierarchical lexicon models resulted in 37.5% SSER.
When an additional external dictionary is used, the hierarchical lexicon models improved the SSER from 36.9%
to 35.4%. These results were obtained using the single word
based beam search algorithm.
Grammar-based Language Models
An important source of errors in state-of-the-art statistical
machine translation systems results from the lack of syntactic structure
of the generated target sentence. The
standard approach of using N-gram models does not seem to provide
enough restrictions in order to produce only syntactic well-formed
sentences. We investigated the use of statistical grammars
as a better model for grammatical well-formed sentences. We showed
that by combining grammar-based and N-gram language models
the translation quality can be improved.
Translation with Cascaded Finite State Transducers
Translation memories can be used as devices for automatic
translation. Their main weakness, however, is poor coverage on unseen
text. One way to overcome this problem is the use of a hierarchical
translation memory, consisting of a cascade of finite state
transducers. A number of transducers is applied to convert sentence
pairs from a bilingual corpus into translation patterns, which are
then used as a translation memory.
A major advantage of this translation method is that it breaks the
middle ground between direct translation methods like simple
translation memory or word based statistical translation and transfer
based methods involving deep linguistic analysis of the input. In
fact, the cascaded transducer approach allows for building quickly a
first version and improving translation quality by gradually adding
more linguistic and domain specific knowledge.
We studied transducers that are partly extracted automatically from a
bilingual corpus, and partly hand-crafted to deal with special
constructs like time or date expressions.
On a test set of 147
German sentences from the VERBMOBIL appointment scheduling and
travel arrangement domain, the SSER (manually evaluated subjective
sentence error rate) of the English translations is 20.3%.