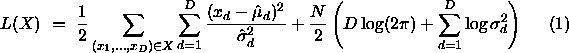Die beschriebenen Konzepte gehen von kontextabhängigen Phonemmodellen aus. Die bisherigen
Implementierungen beruhen auf Triphonen, die durch drei Verteilungen beschrieben werden.
Die zugehörigen D-dimensionalen Merkmalsvektoren
werden als normalverteilt mit Parametern ![]() und
und ![]() angenommen.
Dabei werden die Komponenten jedes Merkmals untereinander als statistisch unabhängig angenommen.
Für die Bewertung einer Klasse setzt man die negative Log-Likelihood-Funktion an, wobei
die klassenbedingten Varianzen und Mittelwerte mittels Maximum-Likelihood-Schätzungen
gewonnen werden.
angenommen.
Dabei werden die Komponenten jedes Merkmals untereinander als statistisch unabhängig angenommen.
Für die Bewertung einer Klasse setzt man die negative Log-Likelihood-Funktion an, wobei
die klassenbedingten Varianzen und Mittelwerte mittels Maximum-Likelihood-Schätzungen
gewonnen werden.
Mit den bekannten Maximum-Likelihood-Schätzern ergibt sich für eine Klasse X die
folgende Log-Likelihood-Funktion