Image Processing Research

At Lehrstuhl für Informatik 6, the experiences gained in the field of automatic speech recognition and natural language processing are applied to the recognition of objects in images. So far, the main emphasis has been put on recognition of single objects, where the main focus is modelling of variability and incorporation of invariances into the statistical model.
Currently a new focus has been put on the modeling of image sequences, especially sign language and gesture recognition, face recognition in videos, and handwriting recognition.
| Theses |
| Deformation Models |


The Euclidean distance has been successfully used e.g. in optical character and object recognition and has been extended by different methods. As the Euclidean distance does not account for any image transformation (such as the affine transformations scaling, translation and rotation) if they are not part of the training corpus, the tangent distance (introduced by [Simard & Le Cun+98]) as described in [Keysers & Macherey+ 01] is one approach to incorporate invariance with respect to certain transformations into a classification system. Here, invariant means that image transformations that do not change the class of the image should not have a large impact on the distance between the images. A more detailed description can be found in [Keysers & Macherey+ 04] and application in medical image classification can be found in [Keysers & Dahmen+ 03].
The image distortion model has been examined at the Lehrstuhl für Informatik 6 of the RWTH Aachen [Keysers & Dahmen+ 03] and further research is presented in [Keysers & Gollan 03]. The image distortion model is an easily implemented method allowing for small local deformations of an image.
For further information on this topic:
- W2D Software, for appearance based image recognition supporting different pixel to pixel deformation models
- Tangent Distance
| Content-based image retrieval |
![]()
FIRE (Flexible Image Retrieval Engine) is our content-based image retrieval system. Content-based Image Retrieval is an active field of research and is getting more and more important by the rise of personal digital cameras.
A large problem in content-based image retrieval is performance evaluation. Recently there are some efforts on this topic:
In our CBIR system FIRE, we have investigated different features, distance functions and ways to measure the retrieval performance of CBIR in different applications, e.g. image retrieval of medical radiographs.
FIRE is available under the terms of the GNU General Public license. Further information on FIRE, the source code, and relevant publication can be found here.
An online demonstration of FIRE is available here. The server usually is running. If it is not up, don't hesitate to complain about it. I am happy to make it run again.
| Object recognition |




Recognition of objects in cluttered scenes is an interesting and important open problem in computer vision and pattern recognition. In close connection to the development of our content-based image retrieval system FIRE we are focussing on this topic.
In contrast to our earlier approaches were the object were modelled holistically now we follow the promising approach of modeling objects as a collection of parts. This approach offers some immediate advantages:
- changes in the relation between parts can be modeled
- occlusion can be handled very well
Currently we are investigating in combinations of discriminative and generative models and in using spatial relationship between the parts.
Some efforts of out work in this area are documented by our CVPR 05 publication and by our results in the PASCAL Visual Object Classes Challenge 2005.
Most of our software for this work is part of the FIRE framework.
| Gesture and Sign Language Recognition |



Developing sign language applications for deaf people can be very important, as many of them, being not able to speak a language, are also not able to read or write a spoken language. Ideally, a translation systems would make it possible to communicate with deaf people. Compared to speech commands, hand gestures are advantageous in noisy environments, in situations where speech commands would be disturbing, as well as for communicating quantitative information and spatial relationships.
A gesture is a form of non-verbal communication made with a part of the body and used instead of verbal communication (or in combination with it). Most people use gestures and body language in addition to words when they speak. A sign language is a language which uses gestures instead of sound to convey meaning combining hand-shapes, orientation and movement of the hands, arms or body, facial expressions and lip-patterns. Contrary to popular belief, sign language is not international. As with spoken languages, these vary from region to region. They are not completely based on the spoken language in the country of origin.
Sign language is a visual language and consists of 3 major components:
- finger-spelling: used to spell words letter by letter
- word level sign vocabulary: used for the majority of communication
- non-manual features: facial expressions and tongue, mouth and body position
A more detailed description can be found in [Dreuw & Rybach+ 07]
For further information on this topic:
- website of Philippe Dreuw
- current issues in Sign Language research
- Benchmark databases for video-based automatic sign language recognition and translation.
| RWTH-OCR - Offline Handwriting Recognition |
The RWTH-OCR system is based on the open-source speech recognition framework RWTH-ASR - The RWTH Aachen University Speech Recognition System, which has been extended by video and image processing methods.
The system has been used for Arabic, Farsi, English, Spanish, and French handwritten texts.
Arabic handwriting recognition -- Due to Parts of Arabic Words (PAWs), white space models and low loop transitions are important in Arabic handwriting recognition.

The visualization shows a training alignment of an Arabic word to its corresponding HMM states, trained with an HMM based system. We use R-G-B background colors for the 0-1-2 HMM states, respectively, from right-to-left. The position-dependent character model names are written in the upper line, where the white-space models are annotated by 'si' for 'silence'; the state numbers are written in the bottom line. Thus, HMM state-loops and state-transitions are represented by no-color-changes and color-changes, respectively.
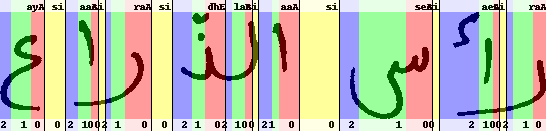
A more detailed description can be found in White-Space Models for Offline Arabic Handwriting Recognition (ICPR 2008). Extensions using Writer Adaptive Training (WAT) and modified MMI training for model adaptation have been presented in Writer Adaptive Training and Writing Variant Model Refinement for Offline Arabic Handwriting Recognition (ICDAR 2009) and Confidence-Based Discriminative Training for Model Adaptation in Offline Arabic Handwriting Recognition (ICDAR 2009).
| Medical Image Processing and Retrieval |
![]()
- We have been very successful in the medical retrieval task of ImageCLEF 2004.
- We have been very successful in the automatic annotation task of ImageCLEF 2005.
| Publications of the Image Processing Group |
For further publications you can either
- have a look at the publications of the chair
- or look at the members personal websites for most up-to-date information
Selected Publications
| 2020 | 2019 | 2018 | 2017 | 2016 | 2015 | 2014 | 2013 | 2012 | 2011 | 2010 | 2009 | 2008 | 2007 | 2006 |
| 2005 | 2004 | 2003 | 2002 | 2001 | 2000 | 1999 | 1998 | 1997 |
-
H. Hanselmann. Alignment and localization in fine-grained image recognition. PhD Thesis, Computer Science Department, RWTH Aachen University, Aachen, Germany, December 2020.


-
O. A. T. Koller. Towards Large Vocabulary Continuous Sign Language Recognition: From Artificial to Real-Life Tasks. PhD Thesis, Computer Science Department, RWTH Aachen University, Aachen, Germany, September 2020.
-
J. Forster. Automatic Sign Language Recognition: From Video Corpora to Gloss Sentences. PhD Thesis, Computer Science Department, RWTH Aachen University, Aachen, Germany, July 2020.
| Acknowledgements |
This work is partially funded by the DFG (Deutsche Forschungsgemeinschaft), and as part of the Quaero Programme, funded by OSEO, French State agency for innovation.
